Les moteurs de recherche évoluent, et avec eux, les règles du jeu du référencement. Désormais, il ne suffit plus de plaire à Google : il faut aussi séduire les intelligences artificielles conversationnelles comme ChatGPT, Mistral, Claude, Gemini et toutes les autres. C’est là qu’intervient la GEO (Generative Experience Optimisation), une nouvelle approche du SEO pensée pour ces IA génératives qui façonnent l’accès à l’information.
Dans ce guide complet, vous découvrirez comment adapter vos contenus, tirer parti des outils d’IA dans vos stratégies SEO, comment apparaître (ou disparaître) des réponses fournies par ces nouveaux assistants. De l’indexation aux applications avancées, en passant par la création de contenu optimisé, ce tour d’horizon vous donnera toutes les clés pour rester visible dans ce nouvel écosystème.
- Le "GEO" c'est quoi ?
- Les principales IA conversationnelles
- Les enjeux
- Se positionner sur Chat GPT et les autres IA
- Origine des sources des IA
- "Query fan out"
- Le "RAG" et le "MCP"
- Les bases de données d'entraînement
- Les sources web des IA
- Stratégies d’indexation
- Les critères de contenus en GEO
- Les critères techniques
- Les critères d'autorité (de liens)
- Tableau récapitulatif
- L’usage de l’IA par les moteurs de recherche traditionnels
- L'IA à des fins de rédaction
- Conclusion
- Foire aux questions
- Articles sources
- Vous pouvez continuer votre lecture avec cette sélection d'article
Le "GEO" c'est quoi ?
Le GEO est un terme en vogue dans l'univers du SEO. C'est l'acronyme de Generative Experience Optimisation (GEO). On utilise aussi des termes tels : AISEO (Artificial Intelligence Search Engine Optimization), AEO (Answer Engine Optimization), AISO (Artificial Intelligence Search Optimization), ASO (Answer Search Optimization).
Le GEO va donc consister à optimiser ses contenus et son site afin de parvenir à les positionner sur les IA conversationnelles (Chat Gpt, Google, Meta AI, etc.). C'est d'une certaine façon le pendant du SEO pour les LLMS1
Les principales IA conversationnelles
Le marché de la recherche par IA est ultra-dominé par ChatGPT2. Les autres grands acteurs en France sont Claude, Mistral AI (société française) et Perplexity.
Les acteurs traditionnels sont bien sûr aussi fortement présents sur le marché : Google avec Gemini et l’AI Overview proposée directement sur le moteur de recherche (sauf en France). On retrouve une interface similaire à l’AI Overview chez Brave Search, Ecosia ou encore Qwant.
Microsoft s’est lui aussi particulièrement impliqué dans les enjeux d’IA. On retrouve des options de recherche dans Bing, dans Edge et dans la suite Microsoft (Copilot, qui utilise ChatGPT).
N’oublions pas des groupes comme X (Grok) ou Meta, qui développent leur propre agent conversationnel. A l'international, il existe également d'importants acteurs chinois (Deepseek, ERNIE (Baidu)...)
Les enjeux
Les IA sont devenues des portes d'entrée importantes pour des millions d'utilisateurs. Elles viennent en complément des moteurs de recherche traditionnels et répondent à des milliards de question dans tous les domaines. Il est bien sûr stratégique pour les entreprises de s'y positionner.
On peut aussi avoir la volonté au contraire de bloquer ces outils pour limiter l'exploitation des contenus ou pour des raisons de performance.
Pour certains sites, l'adaptation aux LLMS peut être une nécessité car ils peuvent les priver d'une partie de leur trafic et donc de leur revenu (en particulier dans le secteur de l'information).
Se positionner sur Chat GPT et les autres IA
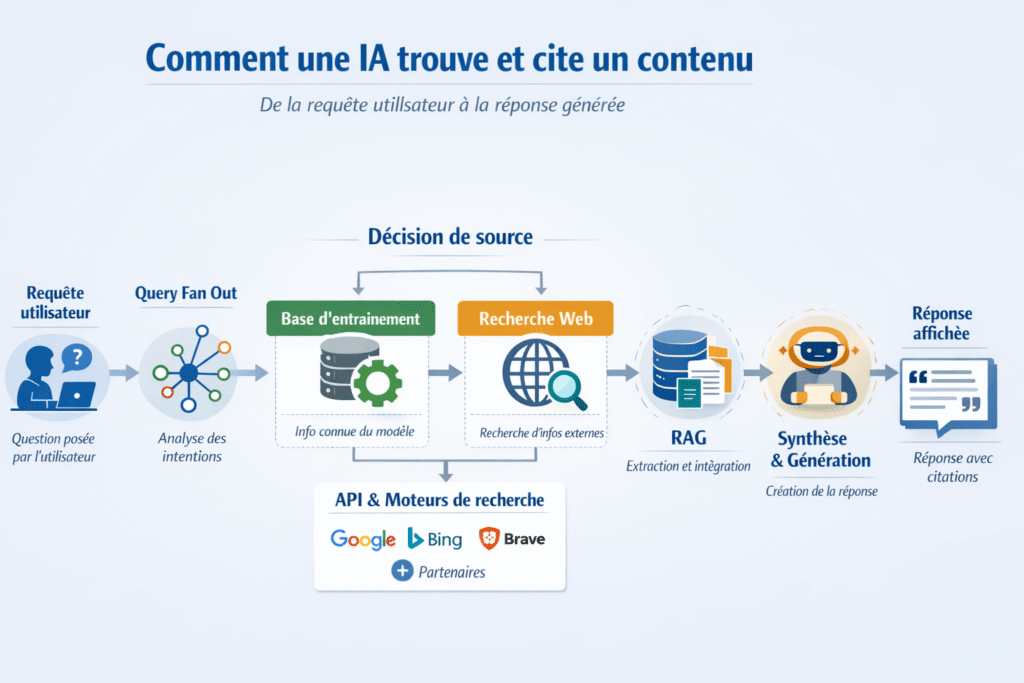
Comme pour les moteurs de recherche, le positionnement sur les IA va s'appuyer sur des critères de contenus, des critères techniques et des critères d'autorité. Avant d'entrer dans leur détail, on doit se pencher sur des notions spécifiques aux LLMS et qui sont fondamentales pour bien comprendre comment se positionner sur ces outils.
Origine des sources des IA
Actuellement, les sources des IA se décomposent en deux grandes parties :
- La base de connaissance pré-établie et régulièrement mise à jour (nommée aussi base de données d'entrainement)
- La recherche web
En gros, quand vous posez une question à Chat GPT par exemple, il va soit considérer qu'il a la réponse dans sa base de donnée, soit il va communiquer avec des sources extérieures (les moteurs de recherche souvent) pour vous donner la réponse adéquate.
Être cité directement par Chat GPT est particulièrement stratégique, la partie liée à la recherche web partage beaucoup de points communs avec le SEO.
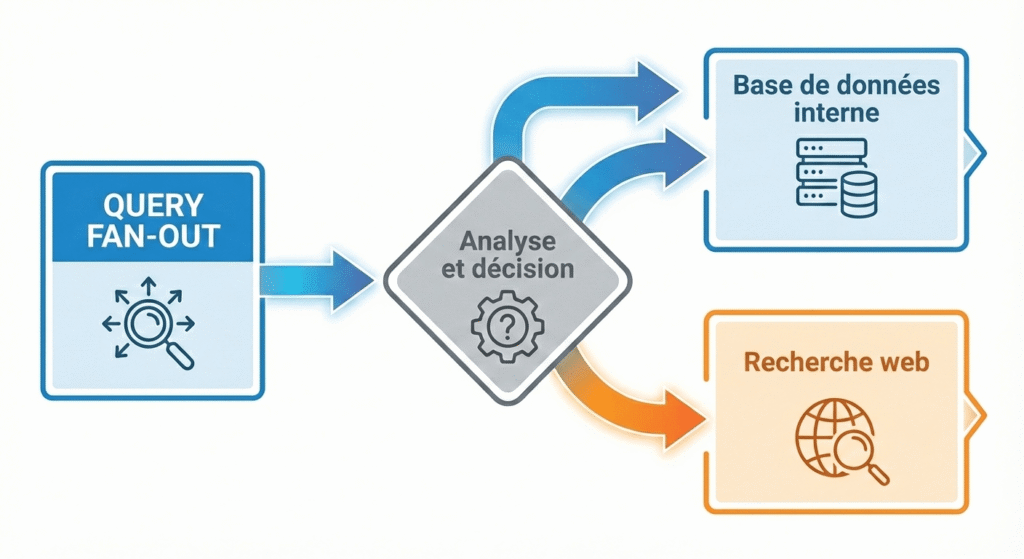
L'étape première en GEO va consister en l'analyse de la requête de l'utilisateur par le moteur d'IA, c'est ce qu'on appelle le "Query fan out". C'est lors de cette analyse que Chat GPT va décider de faire appel à sa base de données d'entrainement ou de rechercher sur le web.
"Query fan out"
Le "Query Fan Out" consiste en l'analyse de votre question, en sa découpe en sous requêtes puis en la proposition d'une réponse synthétique. C'est différent des moteurs de recherche qui vont rechercher une correspondance dans le texte des sites indexés. C'est un concept clé de la Generative Experience Optimisation.
Voici par exemple ci-dessous la décomposition en sous requêtes de la question "Les meilleures destinations touristiques en Europe pour l'été". L'IA cherche à comprendre les différents sens possibles de ma question avant de me répondre et peut être susceptible alors de me demander des informations supplémentaires.
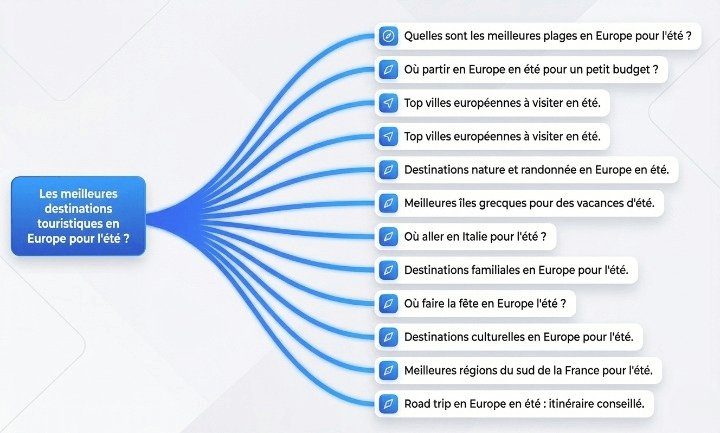
Les conséquences de cela :
- Les LLMS sont très friands de résultats récents, notamment les guide avec l'année en cours
- On va chercher à développer plus en profondeur tous les sous sujets de la requête qu'on vise
- Il est très difficile de faire un suivi de position car il n'y a pas de requête unique.
Pour aller plus loin dans la compréhension des Query Fan Out, on vous conseille la lecture de cet article.
📌 Tips de Laurent : Quand votre contenu s'y prête, ajoutez l'année à votre titre SEO. Quand cela est possible, automatisez la mise à jour de l'année.
Le "RAG" et le "MCP"
Le RAG (Retrieval Augmented Generation) est l'autre concept clé en GEO. Ca va consister à offrir du contenu facilement compréhensible par l'IA afin qu'elle l'utilise pour enrichir ses données.
Cet article du gouvernement retrace bien les enjeux du RAG pour les entreprises : "Guide de la génération augmentée par récupération (RAG)".
Lié aux architectures RAG, le MCP (Model Context Protocol) est un protocole qui permet de fournir aux modèles d’IA des données externes prêtes à l’emploi.
Ces données peuvent provenir d’API de recherche web comme Bing, Brave ou Staan, et sont injectées dans le contexte du modèle sans que celui-ci n’aille directement interroger le web.
Maintenant qu'on a abordé ces deux concepts clé, on peut se pencher plus sur l'origine des sources des IA et la façon de s'y indexer.
Les bases de données d'entraînement
Les IA comme ChatGPT ou d'autres modèles de langage sont entraînées sur d'immenses quantités de textes récupérés sur internet : sites web publics, livres numérisés, articles scientifiques, forums, code informatique et encyclopédies comme Wikipedia. Des bases de données massives comme Common Crawl (voir cet article sur les critères d'indexation de Common Crawl), qui archive des milliards de pages web, servent de matière première. L'objectif est d'exposer ces systèmes à une grande diversité de contenus pour qu'ils comprennent et génèrent du langage de manière cohérente.
Ces données brutes sont nettoyées et filtrées avant l'entraînement pour limiter les contenus toxiques et privilégier les sources fiables. Ces données d'entrainement sont enrichies par des partenariat avec des entreprises privées, par exemple Reddit, l'Associated Press, Axel Springer et Le Monde3 pour ChatGPT.
En GEO, il y a donc un enjeu majeur à être présent sur ces bases de données d'entraînement. On va travailler notamment sa présence dans Wikipédia, les grands médias, sur Reddit, etc.
📌 Tips de Laurent : Si votre entreprise ou vous même n'êtes pas éligibles à Wikipédia, vous pouvez vous tourner vers la base de connaissance Wikidata ou vers des alternatives tels que Everybodywiki ou Wikimonde.
Les sources web des IA
Lors de l'analyse de la requête ("Query Fan Out"), le moteur IA va décider s'il a les données nécessaires pour répondre à la requête ou s'il doit faire appel à des sources extérieures.
Actuellement, dans la majorité des cas les sources extérieures vont être les données des moteurs de recherche via ce qu'on appelle des api. Certaines IA ont communiqué officiellement sur leurs partenariats, d'autres non, voici un récapitulatif de ce que l'on sait actuellement ou de ce qu'on suppose. Ces points peuvent changer rapidement, on essaye de mettre à jour tous les six mois (ou vous pouvez me suivre sur LinkedIn pour des actualisations plus soutenues). Cette partie du GEO est directement reliée au SEO, car pour paraître dans les sources il faut être bien positionnés dans les moteurs de recherche d'origine.
Chat GPT
Chat GPT ne communique pas officiellement sur ses sources. On sait qu'il existe un partenariat entre Open AI (maison mère de Chat GPT) et Microsoft.4 A priori dans ce cadre, Chat GPT peut communiquer avec l'API du moteur de recherche de Microsoft (Bing). Une partie des résultats de Chat GPT proviendraient donc de Bing.
Cependant, de nombreux SEO dont moi même, avons observé que des résultats provenaient de Google, en particulier pour les résultats locaux ou pour des produits. Il semblerait que ces données ne soient pas issues d'accords officiels entre les deux sociétés mais viendraient plutôt d'entreprises tierces telles que Serp API qui extraient les résultats de recherche de Google sans son consentement. En 2026, Google a intenté un procès contre Serp API et amplifie ses protections anti scraping.
Chat GPT semble préférer des données de Google pour leur fraicheur et leur pertinence. Il est possible qu'il fasse le choix entre Google ou Bing lors de l'analyse de nos questions (Query Fan Out). Il n'est pas exclu qu'il communique avec d'autres API de moteurs de recherche (Brave ou à l'avenir l'index européen d'Ecosia / Qwant).
Chat GPT cherche par ailleurs à développer ses propres sources via des partenariats et il dispose de son propre moteur d'exploration du web.
Gemini
De façon assez logique, Gemini étant un outil développé par Google, il utilise les données issues de l'index de Google, de loin le plus fourni au monde ! Gemini va par ailleurs être intégré dans Siri d'Apple5.
Claude (anthropic)
Claude de son côté travaille de manière officielle6 avec le moteur de recherche alternatif Brave (voir notre article "Faire du SEO sur Brave"). L'API de Brave est par ailleurs appréciée des solutions libres ou des LLMS soucieux de la vie privée de leurs utilisateurs.
Mistral
Du côté de Mistral on n'a pas d'informations officielles. Des tests étaient menés avec Brave (qui est partenaire de Mistral pour la partie IA) et ils sont par ailleurs partenaires de Microsoft pour la puissance de calcul. Mes tests m'ont pas permis précisément de déterminer quel moteur ils utilisent entre les deux.
On sait par contre de manière officielle qu'ils ont un partenariat avec l'AFP qui ressort souvent lors des recherches issus du web.
Perplexity
Depuis son origine, Perplexity se définit comme un méta moteur exploitant l'IA pour offrir de meilleurs résultats. Par définition les meta moteurs vont faire appel à plusieurs moteurs de recherche pour essayer d'offrir le meilleur résultat possible. On ne sait pas précisément s'ils ont des accords formels avec Google ou s'ils ont des partenariats avec des entreprises tierces.
Meta AI
L'IA du groupe Meta (Whatsapp, Facebook, Instagram) se base sur Bing et Google7, mais Meta affiche la volonté de se passer à l’avenir de ces moteurs pour développer son propre index8. Ses propres bots d’exploration parcourent d’ores et déjà le web (Meta-ExternalAgent, FacebookExternalHit…).
Grok
Chez Grok, les recherches web se font à priori via l'api de Bing.
Staan
Staan.ai n'est pas un outil d'iA en soit. Il est un fournisseur de sources pour les IA. Il est issu de la collaboration entre Qwant et Ecosia pour développer un index européen indépendant. Il propose des données à plus bas coût et il est spécifiquement pensé à cet usage. Il y a un enjeu à minima pour être présents sur Qwant, Lilo et Ecosia (un peu moins de 10% du marché de la recherche en France et en Allemagne). Il est probable qu'il fournisse à terme des données pour les IA européennes, au moins en partie ou des acteurs internationaux souhaitant se développer en Europe.
Maintenant qu’on connaît les technologies derrière ces outils, comment faire concrètement pour être présent dessus ?
Stratégies d’indexation
Une fois qu'on sait d'où proviennent les résultats, il va s'agir de s'indéxer dessus, c'est à dire d'apparaître dans les résultats et dans un second temps il s'agira de se postionner.
Vous devez tout d'abord veiller à être présents sur les trois principaux moteurs de recherche utilisés par les IA: Google, Bing et Brave.
Pour les deux premiers, il existe des outils pour informer de l'existence de son site via le sitemap et y suivre ses performances. La Google Search Console pour Google et la Bing Webmaster Tool chez Bing. Vous n'aurez pas actuellement de données de Gemini dans la Search Console. Chez Bing, vous avez des informations concernant Copilot mais elles sont mélangées avec celles classiques du web. Pour accélérer votre indexation chez Bing, vous pouvez utiliser le protocole IndexNow.
Concernant Brave, vous ne pouvez pas y soumettre de sites actuellement, vous devez attendre que le site vous découvre. Obtenir des liens entrants permet d'être indexé plus vite. En terme de veille, cela vaut la peine de suivre le déploiement de l'index européen d'Ecosia, de Lilo et de Qwant (soit 7-8% du marché de la recherche).
Outre les actions spécifiques, les bonnes pratiques du SEO en termes d’indexation vont également s’appliquer aux moteurs d’IA.
Vous allez donc doter votre site d’un sitemap, le soumettre à Google et Bing, et l’indiquer dans votre robots.txt. Ca peut être intéressant d'opter pour l'Index Now (un standard permettant d'accélérer son indexation sur Bing). On ne peut pas soumettre de sites directement sur Brave et à suivre le futur index européen d'Ecosia et Qwant.
Veillez aussi à travailler la structure de votre site, à éviter qu’il y ait des pages trop éloignées de la page d’accueil (« règle des 3 clics de profondeur ») et vérifiez qu’il n’y ait pas de pages orphelines. Le cocon sémantique dans une stratégie GEO prend tout son sens, il va fortement faciliter la compréhension de votre structure et la façon dont les éléments communiquent entre eux.
📌 Tips de Laurent : Pour voir si votre site est indexé sur un moteur et voir le nombre de pages, tapez simplement site:monsite.com. Cela est utile notamment sur Brave en l'absence de console de suivi.
Comment bloquer ChatGPT
Vous pouvez aussi avoir le désir de bloquer ChatGPT ou d’autres robots d’exploration d’IA.
Dans ce cas, vous aurez besoin du fichier robots.txt.
Pour bloquer le robot de ChatGPT, ajoutez cette ligne :
User-Agent: GPTBot
Disallow: /Pour bloquer d’autres agents conversationnels, il faut que vous ayez le nom de leur bot d’exploration, et vous les ajouterez alors dans le robots.txt en remplaçant GPTBot par le nom du robot.
Et soyez extrêmement vigilants avec ce fichier robots.txt, car mal utilisé il peut porter préjudice à votre référencement. Lors de mes cours de SEO avancé, je peux aborder sur demande la manière de bien le configurer, les bots qu’on peut bloquer, etc.
🚨 Attention : bloquer ChatGPT n’est pas l’assurance de ne pas voir vos contenus exploités, en particulier si le moteur d’IA a déjà exploré vos contenus et les a déjà intégrés à son index.
Le fichier llms.txt
Le fichier llms.txt est une proposition récente pour aider les IA génératives (ChatGPT, Claude, Gemini, etc.) à mieux comprendre la structure d’un site. Contrairement au fichier robots.txt, il ne bloque rien : il sert à organiser le contenu pour faciliter l’indexation sémantique.
Ce format n’est pas encore un standard reconnu. Il s’agit d’un projet expérimental, sans adoption officielle à ce jour. On peut le générer facilement à présent via Yoast SEO ou encore Rank Math.
John Mueller (Google) a comparé ce fichier à la balise meta keywords9 soulignant son inutilité actuelle. Aucune IA majeure ne confirme son usage, donc sa mise en place reste facultative pour l’instant. À suivre.
🚨 Mon avis : actuellement le fichier LLMS ne semble rien apporter de particulier. Je ne l'utilise pas pour mes sites. En tout cas, en l'état ne payez pas des milliers d'euros pour cela dans l'espoir d'avoir une meilleure visibilité sur Chat GPT.
NL Web
NL Web est une proposition de "framework" développé par Microsoft pour faciliter l'interaction entre le contenu d'un site et les robots d'IA. NL Web est déjà déployé, il peut être activé notamment si vous utilisez Cloudflare. Il se base en partie sur les données structurées.
Deux articles sur le sujet pour aller plus loin :
https://www.sfeir.dev/tendances/nlweb-microsoft-degaine-son-html-pour-le-web-agentique
Dans le domaine de l'ecommerce, Google travaille de son côté sur un protocole pour faciliter l'achat directement dans ses solutions d'IA : l'UCP.
Les critères de contenus en GEO
Toute la première partie de l'article a porté sur l'origine du contenu dans les IA et la compréhension de concepts clés.
A présent que votre contenu est indexable par les IA, il faut le rendre désirable. La bonne nouvelle, c'est que si vous faites déjà du SEO alors votre contenu a déjà une bonne base d'optimisation, il y a surtout quelques leviers sur lesquels il va falloir appuyer en particulier.
Les balises SEO
La balise titre et la balise description gardent toute leur importance. Elles ne seront certes pas affichées dans le résultat du LLM, mais ces données sont renvoyées par l'api quand l'outil souhaite faire une recherche web. Elles vont avoir un rôle déterminant dans la compréhension initiale du sujet de l'article par l'IA.
De façon générale, votre position sur le moteur de recherche détermine pour beaucoup votre traitement ou pas dans l'IA. Donc même dans une optique GEO, vous devez bien travailler ces deux balises.
De même dans le contenu du texte, on fait toujours attention aux H1, H2, etc.
Le contenu
Concernant le contenu, voici quelques conseils généraux glanés auprès d'experts ou issus de mes expérimentations :
- Placez l'information importante en introduction
- Quand l'article s'y prête, ajoutez un cadre "les points clés de l'article"
- Evitez les articles trop longs, un article = une intention de recherche
- Ajoutez des sources
- Veillez à répondre largement au champ sémantique. Ne pensez plus uniquement en termes de mots clé. Exemple sur Chat GPT, on pourra chercher "Où je peux trouver une pizza trois fromages à moins de quinze euros à Paris ?". Avant on aurait simplement mis : "pizza paris pas cher".
- Pensez à bien indiquer l'auteur de l'article et à renvoyer vers ses réalisations (une page LinkedIn par exemple)
- Ajoutez des éléments synthétiques (tableaux, infographies, FAQ)
- Votre déroulé doit suivre un enchainement logique. L'onglet Lisibilité dans Yoast peut notamment vous aider
- Votre article doit apporter une valeur ajoutée par rapport au contenu existant
- Essayez d'enrichir votre contenu d'une vidéo
Ces conseils sont issus de tests de la part d'outils ou de professionnels SEO en France et à l'international. Il ne s'agit pas d'informations officielles de la part des LLMS et la façon de traiter le contenu peut varier dans le temps.
📌 Tips de Laurent : Ajouter une information de qualité qu'on ne trouve nulle part ailleurs est un moyen efficace et éprouvé de sortir dans les moteurs de recherche et potentiellement dans ceux des IA.
Les données structurées
Les données structurées apportent du contexte au contenu. Dans une stratégie GEO, il est important de bien les renseigner.
On travaille notamment celles pour :
- Entités
- Produits
- Commerce local
- FAQ
- Tutos
- Recettes
- Evénements
Vous pouvez regarder sur le site officiel schema.org si des données structurées correspondent à votre secteur d'activité et si elles peuvent ajouter du sens.
Les critères techniques
Les critères techniques vont être globalement les mêmes en GEO et en SEO. On a vu plus haut les points spécifiques concernant l'indexation.
Il peut y avoir des enjeux spécifiques en termes de rendu, le texte encapsulé dans du javascript peut être moins interprété par les IA que par les moteurs de recherche. Il y a aussi des expérimentations visant à proposer une version en MarkDown (MD) pour les robots d'exploration des LLMs.
Et comme en SEO, on travaille bien son arborescence, la performance, les boutons d'appel à l'action, etc.
Les critères d'autorité (de liens)
En GEO, comme en SEO, il est important de travailler l'autorité de son site.
En GEO, l'enjeu va notamment d'être cité dans les sites présents dans la base de données d'entrainement des IA, c'est à dire avant même que Chat GPT et consors ne communiquent avec des sources externes.
Cela peut passer par des articles sponsorisés ou de l'achat de liens auprès de médias référents dans leur domaine. On va également travailler sa présence sur Wikipédia et les autres Wiki ainsi que sur les sites communautaires (Reddit en priorité).
Et enfin, on pense sa présence de manière globale et cohérente. Chaque élément de présence en ligne peut augmenter l'autorité de la marque et offrir une chance supplémentaire d'être cité. En GEO, le site web et les réseaux sociaux font partie d'une stratégie de visibilité commune.
Tableau récapitulatif
| Critère | SEO | GEO | Commentaire |
|---|---|---|---|
| Balise title optimisée | ✔ | ✔ | Utile pour le ranking SEO et la compréhension initiale par les IA |
| Meta description | ✔ | ✔ | Impact indirect en GEO via les API de recherche |
| Structure H1 H2 H3 claire | ✔ | ✔ | Fondamental pour moteurs et IA |
| Correspondance mots-clés | ✔ | ✖ | Le GEO privilégie l’intention et le sens global |
| Analyse d’intention de recherche | ✔ | ✔ | Point commun SEO et GEO |
| Réponse directe à la question | ➖ | ✔ | Central pour ChatGPT, AI Overviews et RAG |
| Contenu synthétique et structuré | ➖ | ✔ | Favorise la réutilisation par les IA |
| Champ sémantique large | ✔ | ✔ | Important pour SEO et compréhension LLM |
| Densité de mots-clés | ➖ | ✖ | Peu pertinente pour les IA génératives |
| Données structurées Schema.org | ✔ | ✔ | Aide SEO et contextualisation IA |
| Présence FAQ, tableaux, encadrés | ✔ | ✔ | Favorise l’extraction d’informations par IA |
| Performance technique (Core Web Vitals) | ✔ | ➖ | Indirect en GEO |
| Indexation Google Bing Brave | ✔ | ✔ | Condition d’accès aux sources IA |
| IndexNow et rapidité d’indexation | ✔ | ✔ | Impact SEO et visibilité dans IA |
| Autorité de domaine | ✔ | ✔ | Facteur fort dans SEO et GEO |
| Backlinks médias reconnus | ✔ | ✔ | Crucial pour crédibilité et données d’entraînement |
| Présence Wikipédia Wikidata Reddit | ➖ | ✔ | Plus stratégique en GEO |
| Présence dans bases d’entraînement | ✖ | ✔ | Spécifique GEO |
| RAG readiness contenu réutilisable | ✖ | ✔ | Critère clé pour IA conversationnelles |
| Contenu récent et daté | ✔ | ✔ | Favorisé par moteurs et LLM |
| Originalité forte | ✔ | ✔ | Différenciation SEO et GEO |
| Marque identifiable et auteur clair | ✔ | ✔ | Renforce E-E-A-T et confiance IA |
| Optimisation pour clic SERP | ✔ | ✖ | GEO vise citation plus que clic |
| Optimisation pour citation IA | ✖ | ✔ | Spécifique GEO |
L’usage de l’IA par les moteurs de recherche traditionnels
L’intelligence artificielle n’a pas attendu l’arrivée de ChatGPT pour s’inviter dans les moteurs de recherche. Depuis des années, elle est déjà là, en coulisses. Google ou Bing s’en servent pour analyser les contenus, affiner le classement des pages et filtrer le spam.
Chez Google, tout s’est accéléré avec RankBrain, puis BERT, et enfin MUM. Derrière ces acronymes, une idée simple : comprendre non plus seulement des mots-clés, mais des intentions, des contextes, des nuances. Le moteur n’indexe plus juste des pages, il tente d’interpréter ce que cherche réellement l’utilisateur. Résultat : un contenu mal structuré, confus ou trop vague a de moins en moins de chances d’émerger.
Mais ce qui bouleverse aujourd’hui les usages, ce sont les réponses générées directement dans la page de résultats. Google déploie progressivement ses AI Overviews, ces encadrés où l’IA synthétise une réponse avant même les premiers liens. Bing fait la même chose avec son Copilot intégré, de même chez Brave, Qwant et Ecosia. À la clé : moins de clics10, une SERP redessinée, et des sites qui deviennent parfois sources sans être visités.
Pour être cité dans AI Overviews, les critères sont la clarté du contenu, sa fiabilité perçue et sa capacité à répondre directement à une intention précise. Cela recoupe à la fois des fondamentaux SEO (structure, expertise, pertinence) et des logiques proches du GEO, où l’IA privilégie des sources compréhensibles, synthétiques et facilement réutilisables.
L'IA à des fins de rédaction
L'usage de l'intelligence artificielle pour la création de contenu a radicalement changé la donne, mais la simple génération de texte ne suffit plus pour obtenir un bon positionnement. Le véritable enjeu réside dans la capacité du rédacteur à structurer ses échanges avec les LLMs pour obtenir un résultat unique et optimisé.
Pour aller plus loin que la simple requête basique, il est essentiel de maîtriser l'art des prompts et de savoir configurer des GPTs spécialisés selon vos propres méthodes de travail. C'est précisément ce que je développe dans cette méthode de rédaction assistée par IA, où je partage mes retours d'expérience et les bonnes pratiques pour transformer ces outils en véritables assistants éditoriaux.
J'y propose notamment deux outils gratuits sur Chat GPT
Conclusion
On voit bien dans ce dossier à quel point le secteur évolue vite, qu’il y a un fort potentiel en termes de positionnement et de trafic et pour améliorer son flux de travail.
Ce qui me semble important c’est de ne pas se reposer uniquement sur ces solutions, sinon on risque d’avoir du contenu non original, les mêmes données que les concurrents, etc.
Il y a aussi une nécessité de faire de la veille afin de comprendre au mieux les évolutions et de se former.
Par ailleurs si l’article vous a plu, je suis en mesure de vous former sur questions par le biais de formations complètes ou de cours individuels.
Foire aux questions
Je ne veux plus que mon contenu soit présent sur ChatGPT, est-ce possible ?
OpenAI propose un formulaire pour demander la suppression de contenus personnels ou sensibles. Pour les sites web, on peut empêcher l’accès futur via le fichier robots.txt, mais cela ne supprime pas les données qui auraient déjà été utilisées pour l’entraînement.
ChatGPT donne de fausses informations me concernant, comment changer cela ?
Vous pouvez signaler une erreur dans l’interface ChatGPT via ce formulaire d’OpenAI. Cela dit, les modifications ne sont pas toujours immédiates ou garanties.
À quoi sert le robot google-extended dans le contexte de l’IA ?google-extended est un robot proposé par Google pour indiquer si un site autorise ou non l’utilisation de son contenu pour entraîner ses modèles d’intelligence artificielle, notamment Gemini. Il ne bloque pas l’indexation classique, seulement l’usage à des fins d’IA générative.
Les moteurs d’IA respectent-ils les droits d’auteur des contenus indexés ?
Pas vraiment. La plupart des IA s’appuient sur du contenu accessible publiquement sans demander d’autorisation. Même si certains acteurs proposent des moyens d’exclusion, il n’existe pas encore de cadre légal solide ni de respect systématique des droits d’auteur.
Comment savoir si ChatGPT génère du trafic vers un site ?
Il est possible de repérer le trafic provenant de ChatGPT dans Google Analytics 4, notamment via les sources de type referral comme chat.openai.com. D'autres outils IA peuvent apparaître de la même manière, par exemple Perplexity.ai ou Mistral. Ce type de trafic est identifiable et mesurable comme n’importe quel autre canal de provenance.
Le trafic provenant de ChatGPT offre-t-il un bon taux de conversion ?
Dans les cas où il y a du trafic, il semble souvent plus qualifié : l’utilisateur est plus avancé dans sa recherche. Mais ce trafic est rare, difficile à mesurer, et dépend fortement du type de contenu ou de produit. Vous pouvez notamment consulter cet article sur ce sujet : https://www.journaldunet.com/seo/1540741-le-trafic-issu-des-moteurs-d-ia-convertit-mieux-que-les-autres-canaux/
Est-il possible de positionner un site dans les réponses de ChatGPT ?
Oui, surtout lorsque ChatGPT utilise la navigation web. Comme il s’appuie sur Bing pour ses recherches en ligne, un site bien positionné sur Bing a plus de chances d’être repris dans ses réponses.
Qu’est-ce que le Generative Engine Optimization (GEO) ?
C’est l’adaptation des pratiques SEO à l’IA générative. Il s’agit d’optimiser ses contenus pour être compris et repris par les moteurs d’IA, en insistant sur la clarté, l’autorité, la réponse directe à des questions, et la bonne structuration du contenu.
En quoi le GEO est différent du SEO ?
Le SEO porte principalement sur Google, les autres moteurs utilisant des logiques proches. En GEO, les acteurs et les modes de fonctionnement sont multiples. Il y a des manières de faire un peu différentes notamment lros de la rédaction et pour être présents dans les sources indexées par les IA.
ChatGPT peut-il être utile pour un site e-commerce ?
Oui, notamment depuis l’apparition de la fonctionnalité shopping intégrée à ChatGPT. Lorsqu’un utilisateur cherche un produit, ChatGPT peut proposer une sélection avec images, descriptions et liens cliquables vers des sites marchands. Les produits affichés sont issus de sources indexées sur le web, ce qui signifie qu’un site e-commerce bien référencé peut y apparaître. C’est aussi un bon outil pour générer des fiches produits, rédiger des contenus d’aide ou automatiser certaines réponses client.
Faut-il structurer différemment ses articles pour les moteurs d’IA ?
Oui, un minimum. L’IA capte mieux les contenus clairs, avec des titres explicites, des paragraphes courts, et une réponse synthétique dès le début. Ce qui est bon pour l’IA l’est souvent aussi pour l’utilisateur.
Comment optimiser un contenu pour qu’il soit repris par une IA générative ?
Il faut répondre précisément à des questions, structurer l’information avec clarté, et affirmer son autorité (données, références, originalité). Les IA reprennent plus volontiers des contenus faciles à analyser et perçus comme fiables.
Quels moteurs se trouvent derrière ChatGPT ?
ChatGPT repose sur les modèles GPT d’OpenAI (GPT-3.5, GPT-4, GPT-4-turbo). Il n’a pas de moteur de recherche intégré par défaut, mais dans certaines configurations (par exemple en mode navigation), il peut utiliser Google et Bing pour interroger le web. Open AI a aussi annoncé qu’à l’avenir les commerçants pourraient certainement soumettre directement leur flux de produits (source : https://help.openai.com/en/articles/11146633-improved-shopping-results-from-chatgpt-search).
Que faut-il savoir sur Gemini, l’IA de Google ?
Gemini est la nouvelle génération d’IA développée par Google. Elle alimente l’assistant conversationnel Gemini (ex-Bard), les AI Overviews dans la recherche, et d’autres produits comme Docs ou Gmail. Elle s’intègre progressivement dans tout l’écosystème Google.
Quelles sont les principales alternatives à ChatGPT ?
Les principales alternatives en Europe sont Claude, Perplexity, Mistral AI, Gemini (Google), Copilot (Microsoft), les IA de Meta et X (Grok).
Quelle est la différence entre SGE et AI Overview ?
SGE (Search Generative Experience) désignait la phase de test des résultats générés par l’IA dans Google Search, accessible via Search Labs. AI Overview est le nom officiel donné à cette fonctionnalité lors de son déploiement grand public. Techniquement, c’est la même technologie, mais SGE était expérimentale, tandis qu’AI Overview est intégrée directement dans la page de résultats.
Quelles données les IA utilisent-elles pour générer leurs réponses ?
Elles s’appuient sur de vastes ensembles de données issus du web, de livres, d’articles, de forums, etc. Certaines IA peuvent aussi interroger le web en temps réel via les api de Bing (Chat GPT), de Google (Gemini) ou de Brave Search (Claude AI). Des réponses proviennent également de partenariats, par exemple Mistral AI a signé avec l’AFP11 et Le Monde avec Perplexity12.
Articles sources
- LLMS signifie Large Langage Model. Avec un -S, c'est un terme fréquemment utilisé dans la communauté SEO pour définir les principales IA conversationnelles du marché (Chat GPT, Gemini, Mistral, Perplexity...) ↩︎
- https://www.abondance.com/20250312-966922-google-search-ecrase-chatgpt.html ↩︎
- https://www.lemonde.fr/le-monde-et-vous/article/2024/03/13/intelligence-artificielle-un-accord-de-partenariat-entre-le-monde-et-openai_6221836_6065879.html ↩︎
- https://openai.com/fr-FR/index/next-chapter-of-microsoft-openai-partnership/ ↩︎
- https://searchengineland.com/apple-siri-google-gemini-deal-467404 ↩︎
- https://www.begeek.fr/anthropic-mise-sur-brave-search-pour-les-recherches-du-chatbot-claude-412971 ↩︎
- https://web.swipeinsight.app/posts/meta-ai-now-incorporates-google-and-bing-search-results-4597 ↩︎
- https://www.theverge.com/2024/10/28/24282017/meta-ai-powered-search-engine-report ↩︎
- https://www.searchenginejournal.com/google-says-llms-txt-comparable-to-keywords-meta-tag/544804/ ↩︎
- https://www.amsive.com/insights/seo/google-ai-overviews-new-research-reveals-how-to-navigate-click-drop-off/ ↩︎
- https://www.afp.com/fr/lagence/notre-actualite/communiques-de-presse/lafp-et-mistral-ai-annoncent-un-partenariat-mondial ↩︎
- https://www.lemonde.fr/le-monde-et-vous/article/2025/05/14/intelligence-artificielle-un-nouvel-accord-de-partenariat-entre-le-monde-et-perplexity_6605885_6065879.html ↩︎
Vous pouvez continuer votre lecture avec cette sélection d'article
- Les 7 outils SEO & IA que j’utilise quotidiennement
- Créer un article SEO avec l’IA : prompts, méthode et bonnes pratiques
- Yoast SEO : 5 fonctionnalités cachées pour booster votre référencement
- Brevo Meeting : le Calendly gratuit que vous cherchiez
- Comment indexer son site sur Brave Search
- SE Ranking : une alternative sérieuse à Semrush
- Comment se positionner sur les IA : SEO, GEO et ChatGPT
- Superprof : mon retour d’expérience et mes conseils pour réussir à y donner des cours
- rel=canonical : un incontournable pour structurer son SEO
- Comment je gagne ma vie en tant que formateur SEO – WordPress ?

À propos de l'auteur
Je suis Laurent Hentz. Mon activité principale est la formation dans le domaine du SEO et de WordPress. Je partage sur ce blog mes retours d'expérience et les outils que j'aime bien. Je suis par ailleurs fondateur du site numipage.com (dédié à l'édition numérique).